
Integrating with Agency Software
The Integration Problem Is SolvedHow AI-powered semantic mapping ends the era of brittle, hand-coded integrationsAlisdair Menzies · March 2026 |
The traditional response is to write a bespoke adapter for each system. A developer reads the API docs, maps the fields by hand, writes transformation code for dates, currencies, and status enums, and deploys it. Repeat for every new integration. It takes weeks per system, it breaks whenever the third party changes their schema, and it never quite handles the edge cases you discover in production.
There is a better way. And it is available right now, using the same AI models that have transformed how developers write code. At Nestsen, we have built a semantic integration layer that lets us onboard a new third-party system in minutes rather than weeks — with the AI doing the field matching, a lightweight human review step catching the ambiguous cases, and the whole mapping stored so that the next customer using the same system benefits from everything we have already learned.

Why integrations are hard
The naive version of the integration problem sounds simple: take a field from system A and write it to system B. The reality is considerably messier.
The challenges cluster into three categories:
1. Schema opacity. Most third-party systems do not publish a clean, accurate schema. Their OpenAPI spec is incomplete, their field names are abbreviated and cryptic, and their documentation lags months behind the actual API. You only understand what a field really means once you see real data flowing through it.
2. Semantic distance. Even when field names are available, the same concept appears under dozens of different names. Your canonical model has monthly_rent_gbp. The third-party system might call it rental_amount, rent_pcm, or MonthlyRentalValue. And it might be in pence rather than pounds.
3. Value transformation. Field mapping is only half the problem. Dates arrive in DD/MM/YYYY format and need to be ISO 8601. Enumerations use single-letter codes that mean something different in every system. Amounts come in pence. Addresses that should be structured objects arrive as a single string. Every integration has its own set of these.
The real cost A typical hand-coded integration with a property management system takes 2–4 weeks of developer time. Multiply that by the number of systems your clients use — Xero, Arthur Online, Fixflo, Rightmove, Zoopla, Sage — and the integration backlog becomes a strategic bottleneck. |
The semantic mapping approach
The key insight is that field matching is fundamentally a reasoning problem, not a pattern-matching problem. When an experienced developer looks at an unknown schema, they are not doing string similarity — they are reading field names, looking at sample values, and applying domain knowledge. They know that a UK field containing values like "SW1A 2AA" and "M1 1AE" is a postcode, regardless of what the field is called.
Large language models can do exactly this kind of reasoning. Given a third-party schema with field names, descriptions, and sample values on one side, and your canonical target schema with rich descriptions on the other, a model like Claude can propose accurate field mappings with confidence scores and written reasoning — in seconds.
Four components
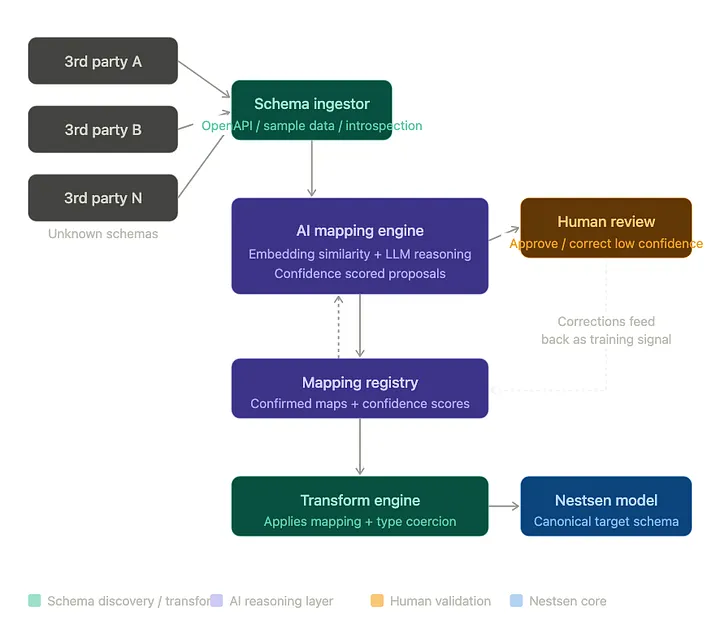
The system breaks into four services, each with a clear responsibility:
1. Schema ingestor — discovers the third-party schema from whatever source is available: an OpenAPI specification, raw JSON sample payloads, CSV headers and rows, or a GraphQL introspection result. The critical output is not just field names but sample values extracted from real data. Those sample values are the single biggest lever on AI match quality.
2. AI mapping engine — the core of the system. It receives both schemas and calls the AI model with a carefully constructed prompt that emphasises sample-value reasoning. The response is structured via tool use — not a free-text reply asking for JSON, which is less reliable. Each proposed mapping carries a confidence score (0–1), a written explanation, and a transformation specification if the values need converting.
3. Mapping registry — stores every confirmed mapping and builds the system's network effect. When the second customer using Arthur Online onboards, all previously confirmed mappings for that system are passed to the AI as strong priors. The AI proposes them with much higher confidence, reducing the human review burden. Over time, common third-party systems become effectively solved.
4. Transform engine — applies confirmed mappings to real incoming records at runtime. It handles date reformatting, enum remapping, unit conversion, type casting, and nested object construction from flat paths. Every incoming record from Arthur Online arrives shaped like a Nestsen canonical property.
Confidence banding: the human stays in the loop
One of the most important design decisions in the system is that the AI never acts autonomously on ambiguous matches. Every proposed mapping gets sorted into one of three bands based on confidence score:
Band | Behaviour |
Auto (≥ 92%) | Applied silently. No human review required. Examples: email → email, address.postcode where sample values confirm UK postcodes. |
Review (70 – 91%) | Applied immediately, but flagged for human review in the dashboard. The mapping is live but annotated as "pending confirmation". |
Manual (< 70%) | Blocks until a human explicitly approves. Data does not flow through this field until confirmed. The AI's written reasoning is shown to the reviewer. |
This keeps onboarding fast for the easy cases — most fields in well-documented systems map at 95%+ confidence and require no human intervention at all. The human review queue only contains the genuinely ambiguous cases, with the AI's reasoning already written out to make the decision easy.
The correction feedback loop When a human reviewer changes an AI-proposed mapping, that correction is logged separately. This data tells you which field mappings the AI consistently gets wrong for a given system — and those corrections improve future prompts, either as additional examples or as explicit cautions in the system prompt. |
What this looks like in practice
Arthur Online is a common property management system used by UK letting agents. Their API uses field names like property_class (FL, HO, HM for flat, house, HMO), monthly_rental_amount (in pence, not pounds), owner_contact_id (a reference to their internal contact record), and address_town (rather than city). None of these match Nestsen's canonical field names directly.
When we onboard a new Arthur Online integration, we pass a handful of real sample records to the schema ingestor. The AI sees that monthly_rental_amount contains values like 120000 and 295000 and reasons — correctly — that these are pence, proposing a unit conversion transformation alongside the field mapping. It sees that property_class contains "FL", "HO", "HM" and maps them to our enum values of flat, house, hmo with 95%+ confidence. It handles the date reformatting for listed_date automatically.
The entire onboarding — from raw sample data to an active mapping — takes under a minute of compute time, plus whatever time a reviewer needs to approve the handful of lower-confidence fields. From the second Arthur Online customer onwards, most fields arrive already confirmed from prior integrations and the review queue is near-empty.
Why this matters for property management specifically
Property management software sits at the intersection of an unusually fragmented ecosystem. Letting agents use different accounting packages, maintenance systems, portal feed formats, and communication tools — and the mix varies by geography, company size, and personal preference.
The integration targets where semantic mapping pays off most immediately are:
Accounting systems — Xero, Sage, QuickBooks, FreeAgent all have completely different chart-of-accounts structures and transaction models
Maintenance platforms — Fixflo, Property Inspect, and others each have their own job, contractor, and status data models
Portal feed formats — Rightmove and Zoopla use different XML schemas for property listings
Legacy back-office systems — many agents run software from the early 2000s with undocumented schemas that only reveal themselves through sample data
In each case, the semantic mapping approach reduces integration time from weeks to minutes, eliminates the bespoke adapter maintenance burden, and — critically — improves with scale. The fiftieth Xero integration is dramatically easier than the first.
The technical architecture at a glance
For teams building on NestJS and Postgres, the implementation maps cleanly to the existing stack:
Component | Technology |
Schema ingestor | NestJS service — handles OpenAPI, JSON, CSV, GraphQL |
AI mapping engine | Anthropic Claude via tool_use (structured output) |
Mapping registry | Postgres via Drizzle ORM — company_id scoped for multi-tenancy |
Transform engine | Pure TypeScript — no external dependencies |
REST API | NestJS controller — onboard, review, confirm, transform endpoints |
The system is designed as a self-contained NestJS module. Drop IntegrationModule into your AppModule imports and inject IntegrationOrchestratorService wherever your sync workers or webhook handlers need to transform incoming data.
On model choiceThe AI mapping engine uses Claude Opus by default — quality matters more than speed here, since onboarding is a one-time operation per system. The transform engine that runs on every incoming record is pure TypeScript with no AI calls at runtime, so there is no per-record AI cost once a mapping is confirmed. |
The integration problem, solved
The era of hand-coding bespoke adapters for every third-party system is ending. The combination of AI reasoning, structured output, confidence-banded human review, and a learning registry that improves with every confirmed mapping makes it possible to connect a new system in minutes rather than weeks — and to get better at it automatically as your customer base grows.
At Nestsen, this means that when a letting agent tells us they need their Xero integration live by the end of the week, the answer is yes — not "we'll put it in the roadmap." That kind of responsiveness is a meaningful competitive advantage in a market where integrations are still largely a manual, developer-intensive process.
The approach generalises beyond property management. Any domain with a stable canonical data model and a fragmented third-party ecosystem — legal tech, healthcare, construction, logistics — can apply the same architecture. The semantic mapping layer is not specific to property. The confidence thresholds, the registry network effect, and the correction feedback loop work wherever the problem exists.
Share this article
See Nestsen in action
Join property managers across the UK who have cut response times, reduced compliance risk and kept tenants happier with Nestsen.
Book a free demo →You might also like

The £0 Maintenance Issue That Turned Into a £20,000 Shock
26 March 2026

What “Good” Property Maintenance Actually Looks Like
25 March 2026

Why Property Maintenance Still Feels Like 1998 (And Why That’s About to Change)
22 March 2026

The Property Management System Most UK Letting Agents Use (And Why It’s Starting to Break)
12 March 2026